The last blog post in the Microsoft SQL Server R Services series covered some performance related parameters of sp_execute_external_script, (@parallel and @r_rowsPerRead), and it touched a little bit on SQL Server Compute Context.
After I published the post, I received an email from Umachandar Jayachandran who is a Principal Program Manager in the SQL Server team and is working on integration of R, Python and other runtimes into SQL Server (basically, he knows this “stuff”). In the mail, he said that I was somewhat incorrect in what I said about how the SQL Server Compute Context (SQLCC) works.
So I decided to write a post to correct my mistakes, and this is it. While I wrote this post I realized that there are more to the SQL compute context that meets ones eye, so I will - in all likelihood - write more posts about SQLCC.
To see other posts (including this) in the series, go to sp_execute_external_script and SQL Server Compute Context.
Before I begin I want to say a very big THANK YOU to Umachandar as well as Nellie Gustafsson who also is a SQL Server Program Manager at Microsoft. Without them making me see the “errors of my way” I would not have been able to write this post.
A little bit of background first.
Background
We all know how SQL Server supports parallelism, whereby it decides whether to execute a statement in parallel or not, and the MAXDOP setting defines the number of processors executing the statement. Parallel execution is also supported when executing sp_execute_external_script by setting the @parallel parameter to 1.
NOTE: You are not guaranteed to execute in parallel even if you set the parameter. SQL Server decides whether the statement you want to execute should be executed in parallel or not.
So, if SQL decides that it can execute in parallel, what happens is that multiple SqlSatellite instances and connections are created. Multiple BxlServer.exe processes host the SqlSatellites, and SQL Server acts as a coordinator and sends data to the various SqlSatellites:
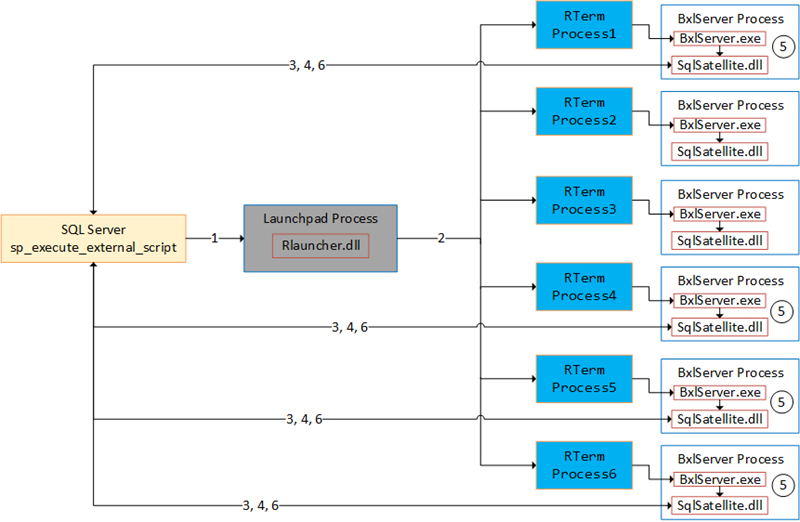
Figure 1: Parallel Execution
Figure 1 tries to illustrate executing external script in parallel with a MAXDOP setting of 6 (6 processes used). The numbers in the figure are:
- We call
sp_execute_external_scriptand SQL Server calls into the launchpad service. - The launchpad service creates RTerm processes which in turn creates BxlServer processes. Based on
MAXDOP, multiple executing processes “spin up”. - TCP connections from the SqlSatellite in the executing processes get established.
- SQL server sends input data to the SqlSatellites.
- The
BxlServer.exeprocesses the data. - SQL Server receives data back from the individual SqlSatellite.
In Figure 1 you see how the execution is in parallel and how SQL Server acts as a coordinator. What I mean with that is that the SqlSatellites make connections to SQL Server, SQL Server sends batches of data to the SqlSatellites, the BxlServer processes handle the data, and finally, SQL receives results back from the SqlSatellites. The good thing about how this works is that it does not matter whether you use RevoScaleR or CRANR functions, they execute in parallel regardless.
The downside with this type of parallel execution (@parallel = 1) is that the processes are independent of each other:
- SqlSatellite makes independent connections to SQL Server.
- SQL Server sends individual batches of data to the SqlSatellite.
- The BxlServer processes hosting the SqlSatellites processes the data.
- SQL Server receives results back from the SqlSatellites.
Why this is a downside is that, as the data is processed independently, if your data has dependencies between different rows (like creating models), there is a high risk that different processes process the dependent rows. We saw that in sp_execute_external_script - III where we had code like so:
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
pid <- Sys.getpid()
myModel <- rxLinMod(y ~ rand1 + rand2 + rand3 + rand4 + rand5,
data=InputDataSet)
model <- serialize(myModel, NULL);
modelbinstr = paste(model, collapse = "")
OutputDataSet <- data.frame(ProcessId = pid,
nRows=myModel$nValidObs,
theModel = modelbinstr)'
, @input_data_1 = N'SELECT TOP(2400000) y, rand1, rand2, rand3,
rand4, rand5
FROM dbo.tb_Rand_3M
WHERE rand5 >= 10
OPTION(querytraceon 8649, MAXDOP 4)'
, @parallel = 1
WITH RESULT SETS ((ProcessId int, Rows int NOT NULL,
ModelAsVarchar nvarchar(max) NULL));
Code Snippet 1: Model Creation in Parallel
The code in Code Snippet1 is supposed to create a model from some random data and then it outputs the serialized model as a string. However when we execute the code in Code Snippet 1 we get a result looking like so:

Figure 2: Parallel Model Creation
Oh, that was probably not what we wanted - four different models from four different process id’s. We see that the models are different based on the outlined, in red, part of Figure 2. So what we have seen right now should tell us that executing in parallel is not always a good thing.
At this stage, you may wonder if everything you have read about RevoScaleR being optimised for Big Data and parallel processing if that is just a marketing ploy? No, it is not, it is correct that the RevoScaleR functions are optimised, and have parallel capabilities. However, for parallel processing, they need the help of the SQL Server Compute Context.
Housekeeping
Before we “dive” into today’s topics let us look at the code and the tools we use today. This section is here for those who want to follow along in what we are doing in the post.
Helper Tools
To help us figure out the things we want, we use Process Explorer:
- Process Explorer is used to look at running processes.
Code
This is the database objects we use in this post:
USE master;
GO
SET NOCOUNT ON;
GO
DROP DATABASE IF EXISTS TestParallel;
GO
CREATE DATABASE TestParallel;
GO
USE TestParallel;
GO
DROP TABLE IF EXISTS dbo.tb_Rand_50M
GO
CREATE TABLE dbo.tb_Rand_50M
(
RowID bigint identity PRIMARY KEY,
y int NOT NULL, rand1 int NOT NULL,
rand2 int NOT NULL, rand3 int NOT NULL,
rand4 int NOT NULL, rand5 int NOT NULL,
);
GO
INSERT INTO dbo.tb_Rand_50M(y, rand1, rand2, rand3, rand4, rand5)
SELECT TOP(50000000) CAST(ABS(CHECKSUM(NEWID())) % 14 AS INT)
, CAST(ABS(CHECKSUM(NEWID())) % 20 AS INT)
, CAST(ABS(CHECKSUM(NEWID())) % 25 AS INT)
, CAST(ABS(CHECKSUM(NEWID())) % 14 AS INT)
, CAST(ABS(CHECKSUM(NEWID())) % 50 AS INT)
, CAST(ABS(CHECKSUM(NEWID())) % 100 AS INT)
FROM sys.objects o1
CROSS JOIN sys.objects o2
CROSS JOIN sys.objects o3
CROSS JOIN sys.objects o4;
GO
Code Snippet 2: Setup of Database, Table and Data
The code above, (Code Snippet 2), creates a database - TestParallel and one table:
dbo.tb_Rand_50M- This table contains the data we want to analyse. Yes, I know - the data is completely useless, but it is a lot of it, and it helps to illustrate what we want to do.
In Code Snippet 2 we also see how we load 50 million records into the dbo.tb_Rand_50M. Be aware that when you run the code in Code Snippet 2 it may take some time to finish due to the loading of the data.
SQL Server Compute Context
In sp_execute_external_script - III we spoke about as part of the functionality in RevoScaleR is the ability to define where a workload executes. By default, it executes on your local machine, but you can also set it to execute in context of somewhere else: Hadoop, Spark and also SQL Server. For this post it is the the SQLCC that interests us.
The SQLCC is not only available from within SQL Server, but also from desktop applications, like Visual Studio, RStudio and so forth. To demonstrate the ability to execute in a separate context we use Visual Studio and some R code:
- Open Visual Studio
- Create a new R project.
In the editor you now have an empty .R file.
NOTE: You do not have to use R, you can if you want to use Python as well.
In the .R file enter following code:
# set up the connection string
sqlServerConnString <- "Driver=SQL Server;server=.\\\inst2k17;
database=testParallel;
uid=<the user id>;pwd=<the password>"
mydata <- RxSqlServerData(sqlQuery = "SELECT y, rand1, rand2,
rand3, rand4, rand5
FROM dbo.tb_Rand_50M",
connectionString = sqlServerConnString);
system.time(print(
myModel <- rxLinMod(y ~ rand1 + rand2 + rand3 + rand4 + rand5,
data = mydata)));
Code Snippet 3: R Code - Local Compute Context
As we see in Code Snippet 3, we create a linear regression model over the 50 million rows in the dbo.tb_Rand_50M table and we measure the time it takes (system.time()). As no compute context is defined the code runs under the local context in one thread.
Before we execute the code we should start up Process Explorer to see what processes are involved when running the code:
- Run Process Explorer as admin.
- Navigate to the
devenv.exeprocess in Process Explorer.
Notice how, under the devenv.exe process, there is a node for Microsoft.R.Host.Broker.exe. Under that node are two Microsoft.R.Host.exe nodes which in turn hosts BxlServer.exe. This is in line with what we discussed in Internals - VIII about hosting of R processes.
When you execute the code in Code Snippet 3 the output in Process Explorer looks something like so:
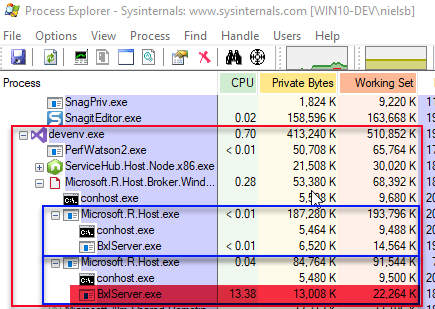
Figure 3: Local Context Execution
In Figure 3 we see the devenv.exe process outlined in red and the two Microsoft.R.Host.exe processes outlined in blue. The second Microsoft.R.Host.exe process shows how the local BxlServer.exe process (highlighted in red) handles the execution of the code. We see this as the CPU value is greater than 0.01. As the process is local, it also means that the process retrieves all data it needs from wherever the data resides. So this is what executing in the local context looks like, oh and before we go any further, please make a note of the output from the system.time() call. On my machine, it is ~40 seconds.
Let us now see what it looks like when we execute in the SQL Server compute context. To enable the SQL Server compute context we only need to add a couple of lines of code from what we saw in Code Snippet 3:
# set up the connection string
sqlServerConnString <- "Driver=SQL Server;server=.\\\inst2k17;
database=testParallel;
uid=<the user id>;pwd=<the password>"
# set up a compute context
sqlCtx <- RxInSqlServer(connectionString = sqlServerConnString,
numTasks = 1)
# set the compute context to be the sql context
rxSetComputeContext(sqlCtx)
mydata <- RxSqlServerData(sqlQuery = "SELECT y, rand1, rand2,
rand3, rand4, rand5
FROM dbo.tb_Rand_50M",
connectionString = sqlServerConnString);
system.time(print(
myModel <- rxLinMod(y ~ rand1 + rand2 + rand3 + rand4 + rand5,
data = mydata)));
Code Snippet 4: R Code - SQL Server Compute Context
In the code above we use the RxInSqlServer() function to indicate we want to execute in a SQL context. The connectionString property defines where we execute, and the numTasks property sets the number of tasks (processes) to run for each computation, in Code Snippet 4 it is set to 1 which from a processing perspective should match what we do in Code Snippet 3. Before we execute the code in Code Snippet 4 we do what we did before we ran the code in Code Snippet 3:
- Run Process Explorer as admin.
- Navigate to the
devenv.exeprocess in Process Explorer. - In addition, also look at the
Launchpad.exeprocess in Process Explorer.
When we execute we see that the BxlServer.exe processes under the Microsoft.R.Host.exe processes are idling, but when we look at the Launchpad.exe process we see this:
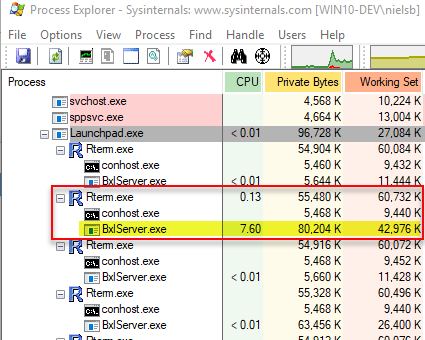
Figure 4: SQL Server Compute Context Execution
Interesting, we see that one of the BxlServer.exe processes under Launchpad.exe is busy (highlighted in yellow). So we see that the code executes in the context of SQL Server. What also is interesting is that the output from system.time(), is on my machine, around 32 seconds - 8 seconds less than when the execution happened in the local compute context! The fact that the execution time is shorter when executing in the SQL Server compute context than when executing in the local context is interesting since we do not do anything different - no more tasks, nothing. Later in this post, we come back to this, but now let us look at using the SQLCC when executing inside SQL Server - like when executing sp_execute_external_script.
SQL Server and SQL Server Compute Context
So the question is now that if we execute from inside of SQL Server, is that not automatically within a SQLCC? It is a valid question since what we see in Figure 4 looks exactly what we saw in quite a few of the posts in the Internals series. In there we saw how the Launchpad.exe process is hosting, via RTerm.exe, a BxlServer.exe server process which processes the data. So let us switch over to SQL Server and SQL Server Management Studio SSMS and try to see if we execute in the SQLCC or not.
You see in Code Snippet 4 how we use the function rxSetComputeContext() to set the compute context. There is also a function to retrieve the compute context you are in: rxGetComputeContext() (in Python it is rx_get_compute_context) which we now use:
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
ctx <- rxGetComputeContext();
show(ctx);'
Code Snippet 5: Use rxGetComputeContext()
So in Code Snippet 5 we call the rxGetComputeContext() function and assign the context to a variable for which we then print out the information from the metadata columns of the variable. This is what we see when we execute the code:

Figure 5: SQL Server Local Compute Context
The highlighted part in Figure 5 says that we do run in the local compute context (RxLocalSeq). So, even when executing in SQL Server we need to explicitly set the SQL Server compute context via RxInSqlServer() and rxSetComputeContext() as we did in Code Snippet 4.
NOTE: The local compute context is named
RxLocalSeq(local sequential) and there is also another contextRxLocalParallel(local parallel), which you can use if you manually manage distributed processing in Hadoop or Spark.
Let us now take a closer look at RxInSqlServer().
RxInSqlServer()
When setting up a SQL Server Compute Context we use the RxInSqlServer function. The function name is the same for both R and Python and the signatures look like so:
RxInSqlServer(object, connectionString = "",
numTasks = rxGetOption("numTasks"),
autoCleanup = TRUE, consoleOutput = FALSE,
executionTimeoutSeconds = 0, wait = TRUE,
packagesToLoad = NULL, shareDir = NULL,
server = NULL, databaseName = NULL, user = NULL,
password = NULL, ... )
Code Snippet 6: R Signature
revoscalepy.RxInSqlServer(connection_string: str,
num_tasks: int = 1,
auto_cleanup: bool = True,
console_output: bool = None,
execution_timeout_seconds: int = None,
wait: bool = True,
packages_to_load: list = None)
Code Snippet 7: Python Signature
When we compare the signatures in Code Snippet 6 and Code Snippet 7 we see they differ somewhat, the reason for this I am not sure about but for now let us look at the parameters that are useful/important when executing sp_execute_external_script.
connectionString/connection_string:
The ODBC connection string to the SQL Server where you want the computations to take place and you can use both Windows authentication mode as well as mixed mode.
Please keep in mind that the connection string for the data source (where you get the data to process from) does not need to be the same as the connection string for the context and the context connection string does not have to point to a different database than the one you execute in.
numTasks/num_tasks:
This parameter is where you set the number of tasks (processes) to run for each computation. The parameter defines the maximum number of tasks SQL Server can use. SQL Server can, however, decide to start fewer processes:
- Dependent on the volume of data (small dataset lower number of processes).
- If other jobs are already using too many resources.
- If num_tasks exceeds the MAXDOP (maximum degree of parallelism) configuration option in SQL Server.
Each of the tasks is given data in parallel and does computations in parallel, and so computation time may decrease as num_tasks increases.
Set the Context
To set the compute context we do the same as in Code Snippet 4:
- Set the connection string which defines where the computations take place.
- Call
RxInSqlServer()to create the context. - Set the context via
rxSetComputeContext(). - Computations using RevoScaleR/revoscalepy functionality is now “automagically” processed in the defined compute context whereas non RevoScaleR/revoscalepy functions run in the local context.
To see what it looks like we edit the code in Code Snippet 4 somewhat:
DECLARE @start datetime2 = SYSUTCDATETIME()
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
# set up the connection string
sqlServerConnString <- "Driver=SQL Server;server=.\\inst2k17;
database=testParallel;
uid=<the user id>;pwd=<the password>"
# set up a compute context
sqlCtx <- RxInSqlServer(connectionString = sqlServerConnString,
numTasks = 1)
# set the compute context to be the sql context
rxSetComputeContext(sqlCtx)
mydata <- RxSqlServerData(sqlQuery = "SELECT y, rand1, rand2,
rand3, rand4, rand5
FROM dbo.tb_Rand_50M",
connectionString = sqlServerConnString);
myModel <- rxLinMod(y ~ rand1 + rand2 + rand3 + rand4 + rand5,
data = mydata);
ctx <- rxGetComputeContext();
show(ctx);'
SELECT DATEDIFF(ss, @start, SYSUTCDATETIME())
Code Snippet 8: SQL Compute Context from sp_execute_external_script
The only difference between the code in Code Snippet 8 and Code Snippet 4 is that we do not use system.time anymore, but instead do aDATEDIFF. We also print out the context at the very end, and when we execute we see that we are in the SQLCC:
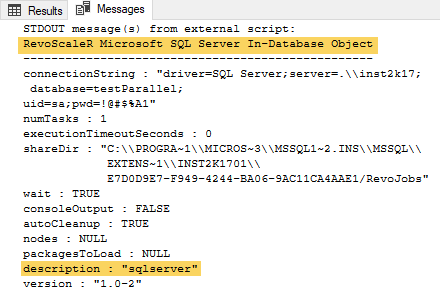
Figure 5: Compute Context Output
The two highlighted parts in Figure 5 shows that we indeed executed inside the SQLCC. As for the execution time; I see in the Results tab in SSMS that the execution took ~30 seconds. If you were to comment out the RxInSqlServer and rxSetComputeContext statements and re-run the code, you’d see the same as we saw above when we used Visual Studio. E.g. executing inside the SQLCC is faster than in the local context, even though it runs in the same database and with the same number of tasks (1). As mentioned in the part where we looked at executing from Visual Studio, something is “going on”, and that is a topic for a future post.
Under the Covers
Now it is time to see how it works when we execute code running in a SQL Server compute context set up with multiple tasks. Remember what we saw in sp_execute_external_script - III when we executed code that ran in parallel:
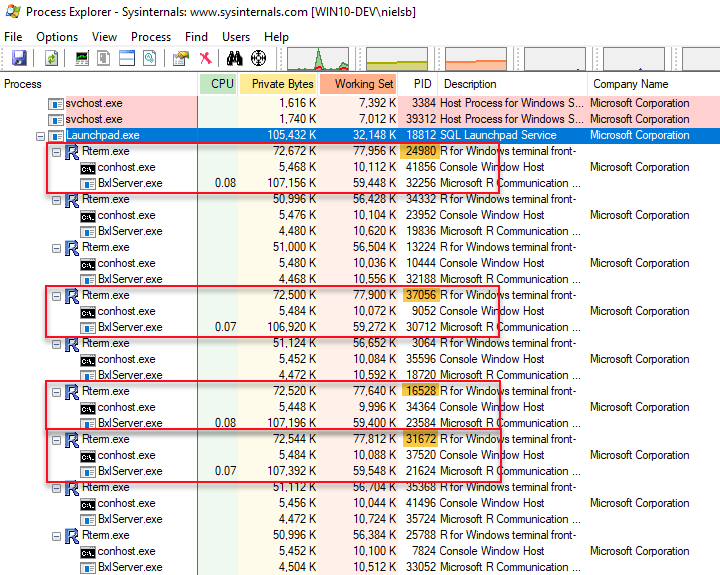
Figure 6: Parallel Execution
What we see in Figure 6 is what we discussed in the Recap; how multiple RTerm and BxlServer.exe processes ran and handled the data independently. So what does it look like when we use the SQLCC, and we execute the code in Code Snippet 8, but the compute context’s number of tasks is set to 4: numTasks = 4?
So to investigate, let us do the following:
- Run Process Explorer as admin.
- Restart the Launchpad service for the SQL Server compute context’s instance (this is to clean-up any RTerm processes).
- Navigate to the
Launchpad.exeprocess in Process Explorer. - Execute the code in Code Snippet 8, but ensure you have changed
numTasksto 4.
While the code is executing, look under the Launchpad.exe process in Process Explorer and you see something like so:

Figure 7: Parallel Execution in Compute Context
Well, that is interesting! In Figure 7 we now see not only the “usual” RTerm and BxlServer.exe processes but also a new hosting process, outlined in red, mpiexec.exe. Underneath the mpiexec.exe process we see the smpd.exe process (outlined in green) and then four RTerm processes with BxlServer.exe processes which handle the workload. So, mpiexec.exe and smpd.exe are parts of Microsoft MPI which is an implementation of MPI which is a communication protocol for programming parallel computers. We talk briefly about MPI a bit later in this post, but first, let us understand the flow.
Flow
We execute sp_execute_external_script and that “spins up” the usual RTerm and BxlServer process which we discussed in quite a few Internals posts. SQL Server creates the compute context via another sp_execute_external_script call to the Launchpad service.
NOTE: Above I say another
sp_execute_external_scriptcall, it is in fact two calls. Hopefully a future post covers why and how there are multiple calls
The Launchpad service creates the mpiexec.exe process which in turns creates the smpd.exe process and the Rterm/BxlServer pairs. If numTasks is set to 1, the Launchpad service does not create a mpiexec.exe process, but instead, it creates a Rterm/BxlServer pair.
MPI
As I mentioned above Microsoft MPI is a Microsoft implementation of the Message Passing Interface standard for developing and running parallel applications on the Windows platform, and it is an integral part of Microsoft HPC (High Performance Computing).
mpiexec & smpd
The mpiexec is called from the launchpad service to start the parallel job. The mpiexec process in turn calls smpd which is a parallel process manager and it launches/monitors RTerm/BxlServer processes.
Summary
- The compute context defines where/what executes a workload.
- RevoScaleR exposes multiple contexts, where SQL Server is one of them.
- You create the SQL Server compute-context by calling
RxInSqlServerfollowed byrxSetComputeContext. - You define how many processes to tun by the
RxInSqlServer’snumTasksparameter. - The execution of the code inside the SQLCC is initiated via two “extra”
sp_execute_external_scriptcalls. - The compute context pushes fragments of the data to the tasks, which processes the data.
- The results are merged back into one result.
~ Finally
If you have comments, questions etc., please comment on this post or ping me.